Finding Patterns in the Noise: Three Years of AI Conversations, Analyzed
From ChatGPT to Claude to TypingMind—what 42,000 messages reveal about tools, costs, thinking styles, and accidentally optimal workflows.
I. THE SPARK
In August 2025, I stumbled upon Eric Porres’ Substack post: “Three Years With GenAI: From Curious to Native.” He’d analyzed 55,889 messages exchanged with ChatGPT, transforming raw conversation data into a meditation on cognitive evolution. The post resonated—not just for what he found, but for the archaeology he practiced.
He’d shared his analysis script. I downloaded it immediately, exported my ChatGPT data, and then... it sat in my backlog for five months.
On January 27, 2026, I finally opened it. But I didn’t stop at replicating Eric’s analysis. I went further.
Not just ChatGPT—I exported data from three platforms: ChatGPT (my starting point, December 2022), Claude Desktop (experimental work since March 2024), and TypingMind (my current primary interface, adopted February 2025). I didn’t just analyze token counts—I pulled real API billing data to understand actual costs, not estimates.
What started as “let me see my ChatGPT patterns” became something deeper: a forensic examination of how I’ve worked with AI across three years, three platforms, and multiple model families.
A note before we begin: These numbers represent only saved conversations across these three primary platforms. They don’t include temporary chats, or my extensive experimentation with Perplexity, Lovable, v0 by Vercel, Manus, and other tools I test regularly. The real cognitive load is higher—this is just what left a traceable record.
What started as curiosity became cognitive archaeology.
This is what I found.
II. THE LANDSCAPE
The Numbers
Over three years, I exchanged 41,932 messages with AI systems across three platforms:
TypingMind: 25,837 messages (61.6%) — 12 months (Feb 2025 - Jan 2026)
ChatGPT: 14,914 messages (35.6%) — 3+ years (Dec 2022 - Jan 2026)
Claude Desktop: 1,181 messages (2.8%) — 22 months (Mar 2024 - Jan 2026)
But these percentages don’t tell the migration story. To see that, you need the timeline.
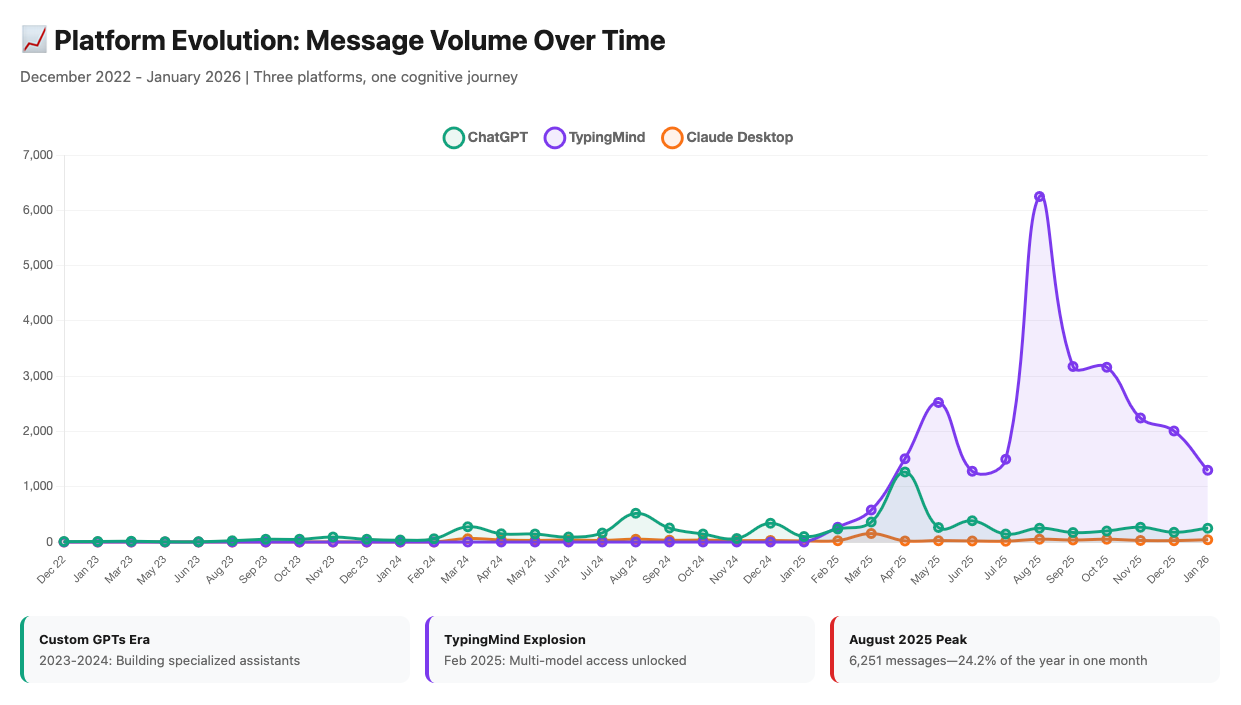
The visual reveals what numbers alone can’t: February 2025 was an inflection point. ChatGPT went from being the tool to being a tool. TypingMind didn’t just replace it—it absorbed the majority of my AI work almost immediately.
From User to Creator to Architect
My relationship with AI didn’t just deepen over time—it fundamentally changed character.
2022-2023: The User
I used ChatGPT for tasks. Asked questions, got answers. Simple consumption.
2024: The Creator
I started building. Custom GPTs became my laboratory for cognitive tool design.
I created 23 Custom GPTs over the year—13 made public for others to use, 10 kept private for specific needs or proprietary work. Some were learning tools, some were analysis frameworks, some were content creation assistants. Not all worked equally well. But together, they represented something important: 46.8% of the GPTs I used, I built myself.
I wasn’t just consuming what others created—I was authoring cognitive capabilities specific to how I work, based on years of experience understanding what I actually needed.
Each GPT was less hypothesis, more extension—cognitive capabilities I wanted available on-demand.
2025-2026: The Architect
TypingMind changed the game. I went from 23 Custom GPTs to working with 68 different agents. But here’s what’s remarkable: 94.3% of my TypingMind conversations use custom agents (vs. 26.9% GPT usage in ChatGPT).
I didn’t migrate from ChatGPT to TypingMind. I migrated from building individual assistants to architecting cognitive systems. The difference isn’t subtle—it’s structural.
What the data shows: I wasn’t just building tools—I was iterating on cognitive infrastructure, keeping what worked, discarding what didn’t.
Note: In August 2025, I shared how I developed a suite of AI assistants that work together through prompt chaining to transform ideas into MVP-ready solutions.
The Token Processing Story
I processed 1.8 billion tokens via APIs to generate 13.8 million words.
Why the massive difference? Because every message in a long conversation re-processes the entire context.
Here’s what actually happens:
Example from my October 2025 usage (one day, Claude Sonnet 4):
Fresh input: 108,982 tokens
Cache write: 931,219 tokens (saving context for reuse)
Cache read: 338,231 tokens (reusing saved context—10x cheaper)
Output: 25,683 tokens
Total tokens processed that day: 1.4 million
Actual unique content: ~135,000 tokens
The 1.4M comes from reprocessing the same context multiple times. Over 12 months, this pattern scaled to 1.8 billion tokens processed but only 13.8 million words actually written.
The difference isn’t waste—it’s the machinery of context persistence. When you’re 200 messages deep in a conversation, message #200 needs to ‘see’ messages 1-199 to maintain coherence. That’s context re-processing at scale.
And because most of those 1.8B tokens were cache reads (10x cheaper than fresh processing), my actual cost was $1,689 instead of $15,358. But we’ll get to that shortly.
Temporal Patterns: When I Think
The heatmap tells a story numbers alone can’t.
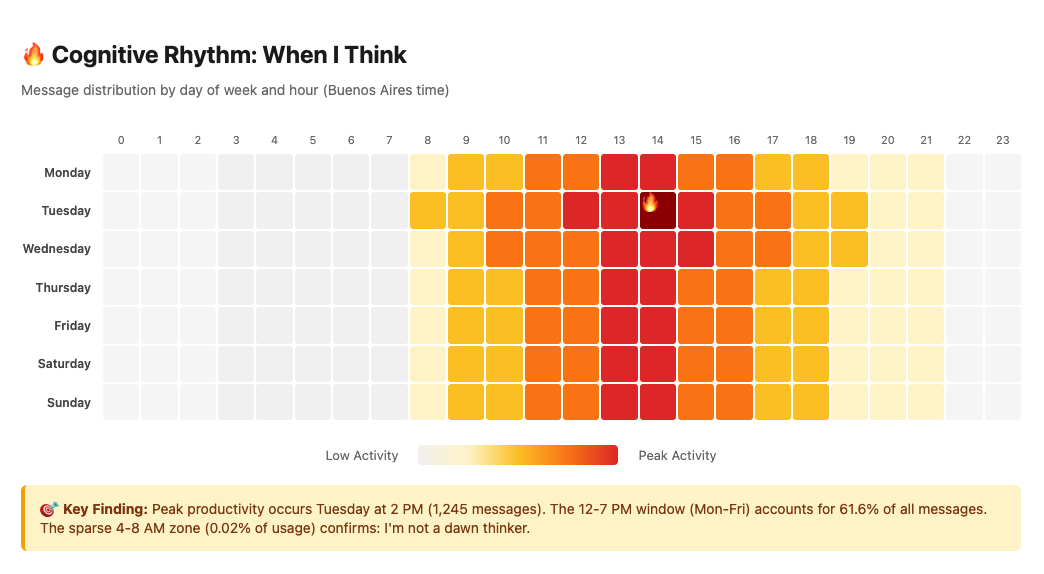
My peak productivity isn’t random: 2 PM on Tuesdays, with 61.6% of all messages concentrated in the 12-7 PM window across weekdays. I didn’t decide this consciously—the pattern emerged from hundreds of work sessions.
The data reveals who you are when you’re thinking hardest. For me, that’s midday-to-evening, Tuesday through Thursday. The sparse early morning hours (4-8 AM: 0.02% of usage) show I’m not a dawn thinker. The occasional late-night spikes (9.5% between midnight-4 AM) capture those rare moments when a problem won’t let you sleep.
Data doesn’t just measure patterns—it reveals the invisible architecture of your attention.
III. THE PUZZLE - WHY COSTS DIDN’T ADD UP
The Question
I wasn’t worried about costs—I was confused by them.
TypingMind reports detailed token usage for every conversation. Multiply those tokens by published API pricing, and you get an expected cost. Simple math.
Except when I did that math: $15,358 for the year.
But my actual monthly bills? Much lower. By mid-year, I knew something didn’t add up. The numbers I was seeing from Anthropic and OpenAI were a fraction of what the token counts suggested I should be paying.
So I pulled the real billing data to understand: $1,689.83 actual cost.
That’s an 89% discrepancy between what the tokens suggested and what I actually paid.
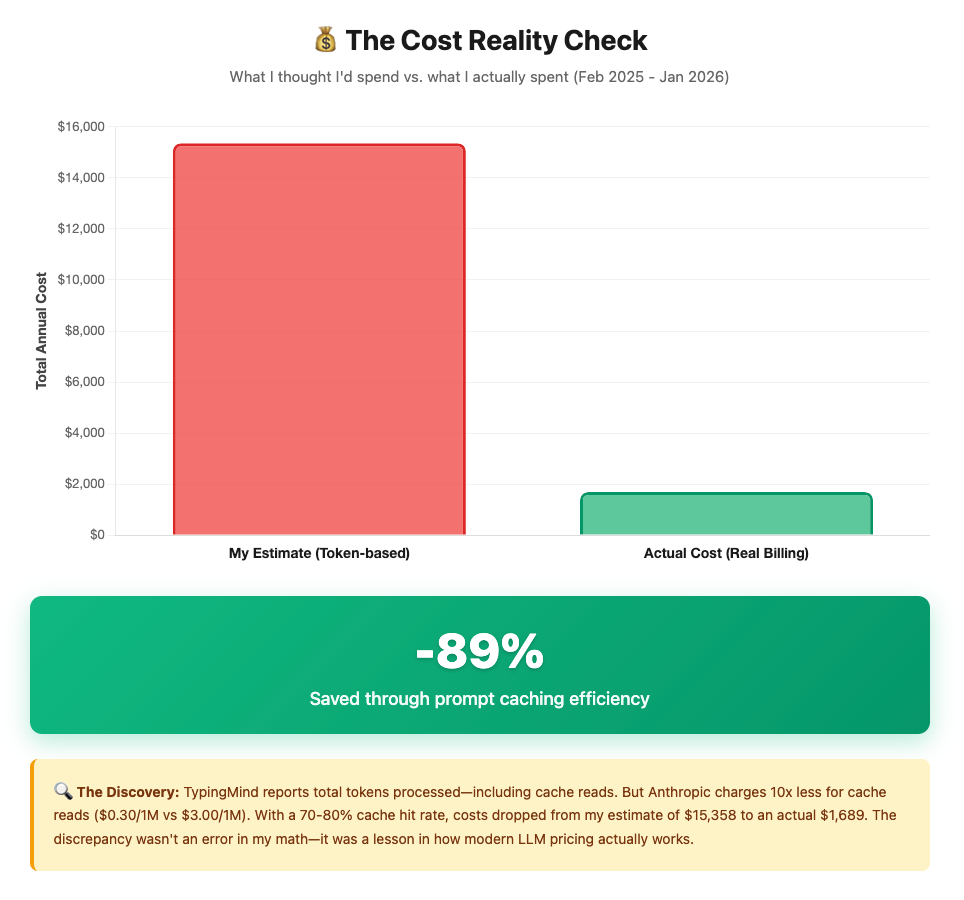
The question wasn't "why am I spending so much?"—it was "why am I spending so little?"
The Answer: Prompt Caching
The $13,668 gap wasn’t an accounting error—it was prompt caching at work.
TypingMind shows you cache tokens, but understanding how they’re actually billed requires checking your provider’s billing data. Here’s what I found when I pulled Anthropic’s real costs:
When you have a long conversation:
First message: The system processes your prompt and caches the context (cache write).
Every subsequent message: Instead of re-processing everything from scratch, it reads the cached context (cache read—10x cheaper) and only processes your new message fresh.
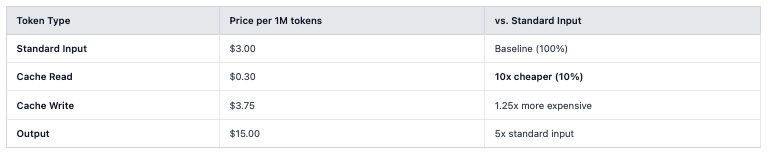
With a 70-80% cache hit rate across my conversations (visible in the billing data), most tokens were processed at $0.30/1M instead of $3.00/1M. That 10x price difference compounds massively.
I’d been calculating costs using TypingMind’s token reports at standard rates. But the actual billing showed the APIs were silently optimizing, reusing context at dramatically lower costs.
Real Example: One Day in October
Here’s what this looks like with real billing data from Anthropic (October 3, 2025, Claude Sonnet 4):
Fresh input: 108,982 tokens → $0.33
Cache write: 931,219 tokens → $3.49 (building cache)
Cache read: 338,231 tokens → $0.10 (90% savings!)
Output: 25,683 tokens → $0.39
────────────────────────────────────
Total cost: $4.31
Without caching: $11.24
Savings that day: $6.93 (62%)Over 12 months, these daily savings accumulated to $13,668.
How My Workflow Accidentally Optimized for Caching
Four factors created near-optimal cache efficiency—none of which I planned:
1. Long conversations (average 52.3 messages/chat in TypingMind)
Each new message reuses 95%+ of previous context as cache reads.
2. Fork strategy (before conversation compaction existed)
When I forked conversations, each fork inherited the parent’s cached context. Every fork started with massive cache reads instead of fresh processing.
3. Extended context windows (16.8% of my Claude usage used 1M token windows)
Larger contexts mean more cacheable material, more reuse, more savings.
4. Sequential work sessions
Working on the same project across multiple sessions meant the cache stayed warm. Context persisted, savings compounded.
I didn’t design this for cost optimization. I designed it for thinking deeply. The cost efficiency was an emergent property of working the way I naturally work: long, iterative, context-heavy conversations.
The puzzle solved itself: I was spending less because my workflow—accidentally, unconsciously—aligned perfectly with how modern LLM pricing rewards context reuse.
Sometimes the best optimizations are the ones you don’t plan.
IV. MULTI-MODEL SYMBIOSIS
The Migration
2022-2024: The GPT-4 Era
For two years, my AI world was simple: ChatGPT, GPT-4 exclusively. I became fluent in one model’s capabilities, built Custom GPTs around its strengths, learned its quirks.
In December 2023, ChatGPT turned one year old. I have a screenshot from that celebration—a small reminder of when this relationship was new, experimental, uncertain.
One year in, I had no idea this was just the beginning.
March 2024: First Exposure to Claude
Claude Desktop arrived. I experimented—131 conversations over 22 months—but it remained a side tool, useful for certain workflows but not my primary interface.
The real shift would come a year later.
February 2025: TypingMind Changes Everything
TypingMind gave me what I didn’t know I was missing: Claude’s reasoning with full customization. Multi-model access (Claude, GPT, Gemini, custom models, and others) in one interface, with custom agents, prompt chaining, and access to 95+ different tools.
The migration was immediate. ChatGPT went from 100% of my AI usage to less than 40%. TypingMind absorbed 61.6% almost overnight.
August 2025: The Pragmatic Shift to Claude
Through July 2025, I used Gemini heavily—and not just because it was free.
Gemini was genuinely good. Google’s models delivered solid results for research, analysis, and experimentation. And yes, the free tier mattered. Living in Latin America, API costs in USD aren’t trivial. I wanted to maximize “reps”—iterations, experiments, learning cycles—without burning through budget. Gemini let me do that while getting quality results.
But August brought a shift. Projects became more complex, requiring deeper reasoning and longer context. Gemini’s free tier limits weren’t enough anymore, and when I compared paid Gemini vs. Claude for the specific work I needed, Claude delivered more consistently for those particular use cases.
The migration to 66.6% Claude wasn’t ideological—it was pragmatic. When free stops working, you pay for what performs. And Claude performed.
Worth noting: I’m currently testing Gemini 3.0 for certain tasks—the newer models have improved and are competitive with Claude for specific use cases. The best model isn’t permanent; it’s contextual—what does this specific task need right now?
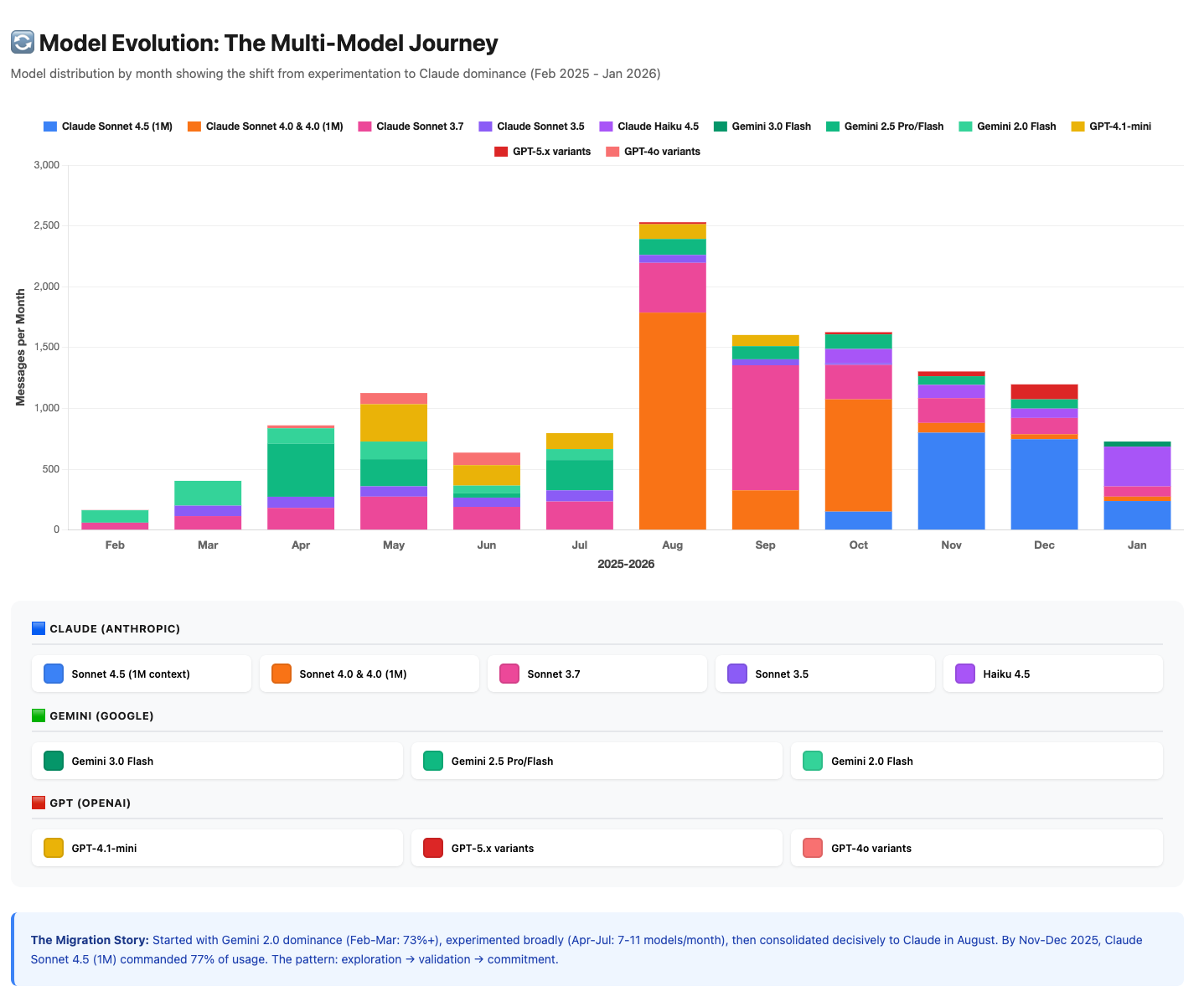
Platform Specialization: Each Tool Found Its Purpose
I didn’t consciously assign roles to each platform—they found their niches organically.
ChatGPT remains in my workflow mostly through inertia and memory. It has years of context about how I work, patterns I’ve built up since 2022. I can use my Custom GPTs there. For quick questions, temporary chats, or practical problem-solving, I default to ChatGPT—not because it’s better, but because it’s familiar and I’m already paying the monthly subscription.
TypingMind became my primary workbench for serious work: AI product development, deep research, business strategy. When I need to think deeply, iterate extensively, or orchestrate multiple tools, TypingMind is where I go. It also has its own memory system that I’ve been building.
Claude Desktop stays relevant for specific needs—mainly when I need artifacts (editable code/documents that I can iterate on), plus it offers a more technical perspective for certain workflows. Now that Claude recently added memory capabilities, there’s an interesting challenge emerging: normalizing my memory across platforms. Right now I have memory built in TypingMind, years of context in ChatGPT, and emerging memory in Claude Desktop. I’m paying subscriptions for both ChatGPT and Claude Desktop, so I use them when they fit the task. It’s an experiment in progress.
The data shows the split (61.6% / 35.6% / 2.8%), but the reality is simpler: TypingMind for deep work, ChatGPT for quick practical tasks and legacy context, Claude Desktop for artifacts and technical workflows. Tools self-selected by friction and capabilities, not by grand design.
Tool Usage: Enabling Higher-Value Work
30.5% of my messages in TypingMind involved tools—7,873 tool calls across 12 months. That’s roughly 1 tool call every 3.3 messages.
Breaking it down:
Sequential Thinking: 2,989 calls (38% of tool usage)
Research tools (Perplexity + Exa + Deep Researcher): 1,417 calls (18%)
Visualization (HTML, Mermaid, Charts, Canvas): 2,095 calls (27%)
Productivity (Jira, Confluence, TODO): 340 calls (4%)
Others (Time MCP, scraping, code context): 1,022 calls (13%)
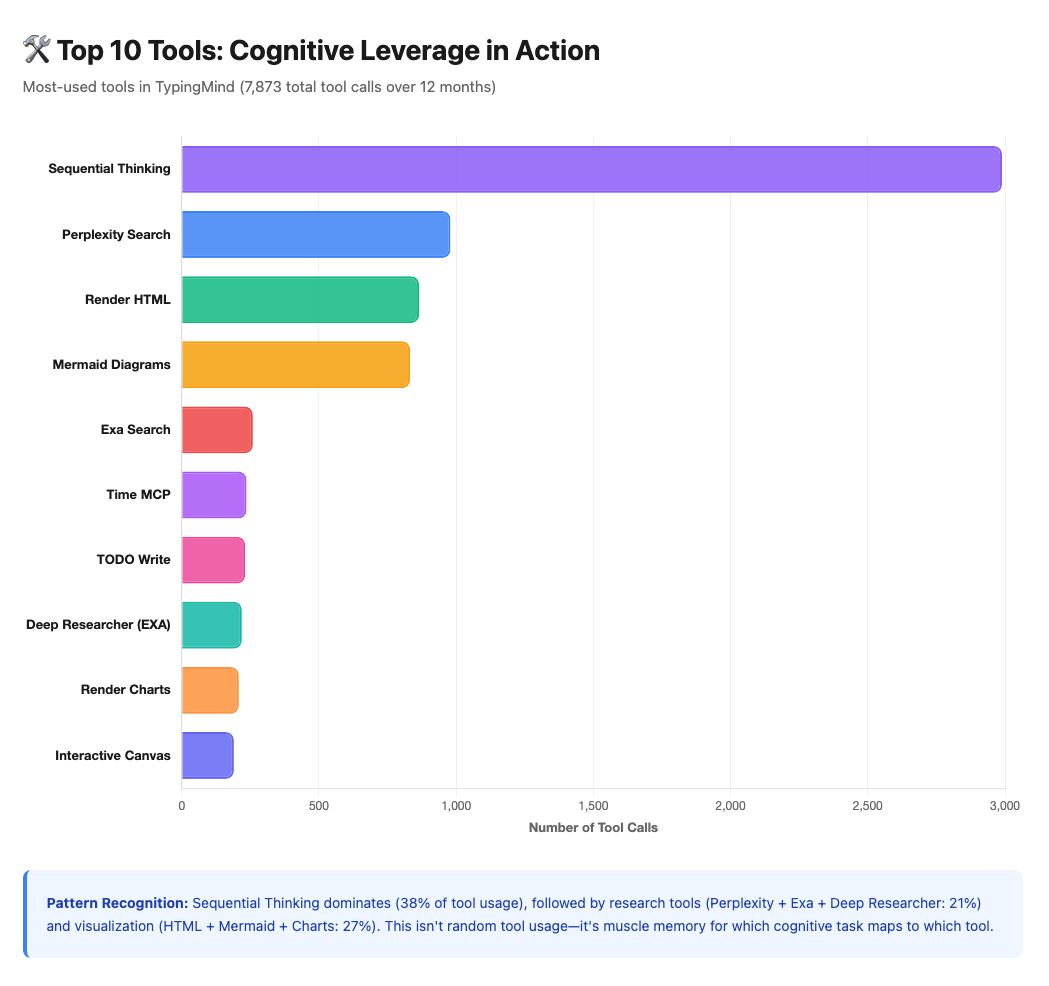
Shows Sequential Thinking dominating, followed by research and visualization tools.
But this isn’t about technical sophistication for its own sake. It’s about enabling higher-value work.
When Sequential Thinking handles structured reasoning, when Perplexity handles research, when Mermaid generates diagrams—I’m freed to focus on synthesis, strategy, and judgment.
The tools don’t replace thinking. They elevate what I think about. Instead of spending mental energy on “how do I research this?” I think about “what does this research mean?” That shift—from execution to interpretation—is where the value lives.
Looking at these tool patterns, I realize: I’ve unconsciously specialized. Sequential Thinking for complex reasoning, Perplexity for research, Mermaid for visualization. I’m not randomly grabbing tools—I’ve developed muscle memory for which cognitive task maps to which tool.
This is craft, not just usage.
V. PATTERNS & THEMES
What I Actually Work On
When I looked at 477 TypingMind conversations categorized by theme, I expected clear boundaries: “this is AI work,” “this is business work,” “this is design work.”
Reality was messier—and more interesting.
77.8% of my conversations span multiple categories. A typical project might start with market research (Business & Strategy), evolve into agent architecture (AI & Machine Learning), and require UX considerations (Design) simultaneously. The categories aren’t separate—they’re interconnected layers of the same work.
Here’s what the analysis revealed:
Main themes (with overlap, so >100% total):
AI & Machine Learning: 245 conversations (51.4%)
Business & Strategy: 187 conversations (39.2%)
Design & UX: 153 conversations (32.1%)
Software Development: 79 conversations (16.6%)
Academic & Research: 70 conversations (14.7%)
Over half my conversations touch AI/ML—unsurprising given my work. But the 39% in Business and 32% in Design reveal something less obvious: I’m not just building AI products; I’m thinking about markets, positioning, and user experience simultaneously.
The strongest connection: AI & Machine Learning + Design & UX appear together in 82 conversations (43.5% affinity). This isn’t coincidence—it reflects how I actually work. I don’t think “let’s build AI” separately from “let’s design UX.” I think: “how does AI enable better UX, and how does UX shape what AI should do?”
But categories are too broad. The real insight comes from subtopics—where the work actually concentrates:
Top 5 subtopics (granular breakdown):
Market Research & Analysis: 16.8% of all conversations
Agents & Orchestration: 8.8%
Prompts & Context Engineering: 8.6%
UX/UI Design: 8.6%
Development Practices: 6.9%
These five account for 49.7% of all cognitive work.
The pattern is clear: within “Business & Strategy,” 54.8% is specifically market research. Within “AI & Machine Learning,” it’s nearly evenly split between building agent systems (34.1%) and engineering how to communicate with them (33.3%). Within “Design,” 67.2% is UX/UI specifically, not branding or content.
I don’t work broadly across domains—I specialize deeply within intersections. Market research informed by AI capabilities. Agent architecture shaped by UX principles. Prompt engineering grounded in understanding how these systems actually think.
This interdisciplinary pattern isn’t strategy—it’s natural consequence. I move between disciplines because my background spans them. The work reflects that.
Cognitive Rhythm: When Deep Work Happens
My productivity follows patterns I didn’t consciously design:
Weekly rhythm:
Peak day: Tuesday (19% of messages in TypingMind)
Lowest day: Monday (10.4%)
Weekend work: 26.6% of messages happen Sat-Sun
Daily rhythm:
Peak hour: 2 PM (9.8% of all messages)
Golden window: 12-7 PM captures 61.6% of usage
Dead zone: 4-8 AM (0.02% of messages - I’m not a dawn thinker)
Consistency:
Longest streak: 46 consecutive days (ChatGPT, 2025)
Active days: 504 days over 3+ years (43.8% of all days)
I didn’t plan Tuesday afternoons as peak productivity time. That’s when hundreds of sessions revealed deep work naturally happens. The sparse early mornings aren’t discipline failure—they’re honest recognition that my brain doesn’t wake up creative at 5 AM.
The data reveals who you are when you’re thinking hardest. For me: midday-to-evening, Tuesday through Thursday, in sessions that sometimes stretch past midnight when a problem won’t let go.
Verbosity & Depth: How Thinking Changed
One striking shift: conversations got dramatically deeper when I migrated to TypingMind.

My prompts in TypingMind are 3.9x longer than in ChatGPT. At first glance, this looks like I just write more. But the real shift was deeper: I changed how I input thoughts.
With TypingMind, I started using MacWhisper—a dictation tool that lets me speak to the AI instead of typing.
Voice unlocked something typing couldn’t: the ability to get ideas down faster and cruder, closer to how they form in my head. Brain dump mode. Stream of consciousness.
There’s a balance in how I work with this. Sometimes I edit the transcription—writing is ritual for me, it gives structure and intention, and that deliberate refinement matters. Other times I don’t—I let the raw brain dump become the prompt, and the AI (specifically, agents I’ve designed for this purpose) helps me find structure in the mess.
The neuro-spicy component means voice often generates better flow—ideas come fast, connections happen, momentum builds. Voice captures that before it dissipates. Then I can manipulate that output, shape it, refine it.
This explains the 3.9x increase in prompt length. It’s not that I’m saying more—it’s that I’m thinking out loud instead of pre-filtering through the typing bottleneck.
The tools didn’t just change what I work on—they changed how ideas move from brain to machine. From typing (filtered, structured) to speaking (raw, exploratory) to AI-assisted structuring.
The Fork Strategy & Context Evolution
Before December 19, 2025, when TypingMind launched Context Summary (conversation compaction), I manually forked long conversations when they hit limits or needed to branch in different directions.
Each fork inherited the parent’s cached context. Those cache reads cost 10x less than fresh processing, making forking accidentally cost-efficient—I was optimizing for thought continuity, and cost optimization emerged as side effect.
Context Summary changed things. Instead of forking into new threads, I can now compress conversation history into condensed summaries, maintaining context without thread proliferation.
I’ve created only 4 Context Summaries since launch (Dec 19), compacting 143 messages across ~1M tokens. It’s too early to compare efficiency versus forking, but it represents an evolution: from manual context management → automatic context compression.
The historical pattern reveals something: technical limitations (pre-compaction) forced me into near-optimal caching strategies without conscious intent. The best optimizations aren’t always designed—sometimes they emerge from working within constraints.
VI. LEARNINGS & FORWARD
What Three Years Taught Me
1. Real cost follows complexity, not volume
I spent $1,689 over 12 months. But 60% of that ($1,022) came in Q4 2025 alone—October through December. Peak month: December at $422.
The cost didn’t correlate with message count. It correlated with project complexity. Months with deep research requiring 1M context windows, extensive cache building, and long iterative sessions cost more. Months with quick queries and shorter conversations cost less.
Learning: Don’t optimize for “fewer messages”—optimize for working on things that matter. The cost reflects the value of the work, not waste.
2. Specialization emerges, it isn’t designed
I didn’t sit down and decide platform roles. The data shows clear patterns—but they emerged organically from hundreds of sessions. Each platform naturally found the friction point where it worked best.
Learning: Let tools find their purpose through use, not through upfront planning. The best workflows aren’t designed—they’re discovered through iteration.
3. Multi-model beats mono-model
Claude dominates my usage (66.6%), but I didn’t arrive there through loyalty. I arrived through pragmatic testing: Gemini for free-tier volume → Claude when I needed consistent performance → currently testing Gemini 3.0 for certain tasks as it improves.
The best model isn’t permanent. It’s contextual—what does this specific task need right now?
Learning: Model loyalty is a trap. Build workflows that can flex across models as the landscape shifts.
4. Tools enable higher-level thinking
30.5% tool usage in TypingMind means roughly 1 tool call every 3.3 messages.
But here’s what matters: I don’t invoke those tools. The agents do. Sequential Thinking activates automatically when complex reasoning is needed. Perplexity fires when research is required. Mermaid generates diagrams when visualization helps.
Learning: The tools don’t replace my thinking—they elevate what I think about. I focus on synthesis, judgment, strategy. The tools handle execution. That shift from “how do I do this?” to “what does this mean?” is where the value lives.
5. The best optimizations are invisible
My workflow accidentally optimized for caching: long conversations, fork strategy, extended context windows, sequential sessions.
I didn’t design this for cost efficiency. I designed it for thinking deeply. The 70-80% cache hit rate, the $13,668 in savings—those emerged as byproducts.
Learning: Optimize for the work itself. Cost efficiency, tool selection, platform specialization—these emerge from doing good work consistently, not from premature optimization.
6. Voice unlocked different cognition
The 3.9x increase in prompt length wasn’t about writing more. It was about speaking instead of typing.
MacWhisper unlocked brain-dump mode—getting ideas down faster, cruder, maintaining flow. Sometimes I edit (writing is ritual, structure, intention). Other times I don’t (let agents structure the rawness). The neuro-spicy component means voice often wins when momentum matters.
Learning: The interface matters as much as the model. Typing filters thoughts through a bottleneck. Voice lets cognition flow more naturally. The right input method unlocks different modes of thinking.
What’s Next
For my workflow:
Continue Claude Sonnet 4.5 (1M) as primary for complex work
Multi-platform flexibility (don’t consolidate)
Voice-first prompting with MacWhisper
Context Summary exploration (analyze efficiency in 3-6 months)
Keep testing Gemini 3.0 contextually
Memory normalization across platforms
Cost-per-project tracking (not just cost-per-month)
For you (if you’re curious):
Export your data (ChatGPT Settings → Data Export)
Look at your own patterns
Don’t benchmark against others—volume isn’t the point, pattern recognition is
Look for: When do you think? What do you work on? How has usage evolved?
The real value isn’t in the numbers—it’s in recognizing transformations already underway. These tools are shaping how you think whether you notice it or not. The data just makes it visible.
Final Reflection
Eric Porres ended his post wondering if he was still human after 55,000 messages with ChatGPT.
I end mine with a different realization:
I’m not using AI—I’ve become a human-AI cognitive system.
These 41,932 messages aren’t consumption records. They’re archaeological evidence of a mind learning to think at distributed scale.
From ChatGPT user to Custom GPT creator to multi-platform agent architect. From typing thoughts to speaking them. From single-model to contextual multi-model selection. From choosing tools to having agents orchestrate tools automatically.
This is what cognitive evolution looks like in the age of AI.
The best optimization isn’t the one you design—it’s the one you become through thousands of iterations. The patterns in my data aren’t strategies I planned. They’re strategies that emerged from working consistently, experimenting continuously, and letting tools find their natural fit.
Three years in, I don’t use AI anymore.
I think through it.
But what does that actually mean? How does distributed cognition work in practice? And what can the shift from consumer to architect teach us about the future of human-AI collaboration?
Coming next:
Part 2: The Architect’s Mindset — A deeper exploration of what these patterns reveal about distributed cognition, interdisciplinary thinking, and designing your own cognitive infrastructure
For now, the archaeology is complete. The patterns are visible. The transformation is undeniable.
Tech Stack for This Article
Creating this piece involved a blend of human reflection and technological assistance. Here are the key tools used in the process:
MacWhisper: For capturing initial thoughts (in Spanish and English) via stream-of-consciousness dictation, feeding directly into the AI assistant.
Personal AI Content Assistant (Built by me using Typing Mind Powered by Claude Sonnet 4.5 (1M)): This custom assistant took dictation and supported the writing process end-to-end—brainstorming, structuring ideas, serving as a thought partner, and refining drafts.
Visual Studio Code + Cloude Code: Used as the development environment to process Eric’s script and kick off a structured project focused on consolidating and processing my personal data across multiple platforms. This setup allowed me to experiment, iterate, and begin transforming dispersed information into a coherent, programmable system.